Election OCR Pipeline
เปลี่ยนภาพถ่ายผลเลือกตั้งที่ยับยู่ยี่ให้กลายเป็นข้อมูลที่เชื่อถือได้
เกี่ยวกับการแข่งขัน
โจทย์
สร้าง OCR Pipeline อ่านผลเลือกตั้งจากใบ สส.4/5 ที่ถ่ายมาจากสนามเลือกตั้งจริง แข่งบน Kaggle
ความท้าทาย
ฟังดูง่าย แต่พอเปิดดูรูปจริงถึงรู้ว่ามันไม่ง่ายเลย — เอกสารถ่ายในสภาพแสงแย่ มีเงาทับ บางใบเบลอ บางใบเอียง ตัวเลขที่เขียนด้วยมือก็อ่านยาก
Platform
Kaggle competition ที่มีข้อมูลจากการเลือกตั้งจริง รวมกว่า 1,000 ใบ สส.4/5 จากสนามเลือกตั้งต่างๆ
ผมไม่ได้พยายามหา "วิธี preprocess ที่ดีที่สุด" เพียงวิธีเดียว — เพราะภาพแต่ละใบมีปัญหาต่างกัน สิ่งที่ดีกับใบนึงอาจไม่ดีกับอีกใบ แนวคิดของผมคือ: ถ้าคนอ่านคนเดียวอ่านไม่ออก ก็ให้คนหลายคนอ่าน แล้วโหวตกัน
Pipeline 5 ขั้นตอน
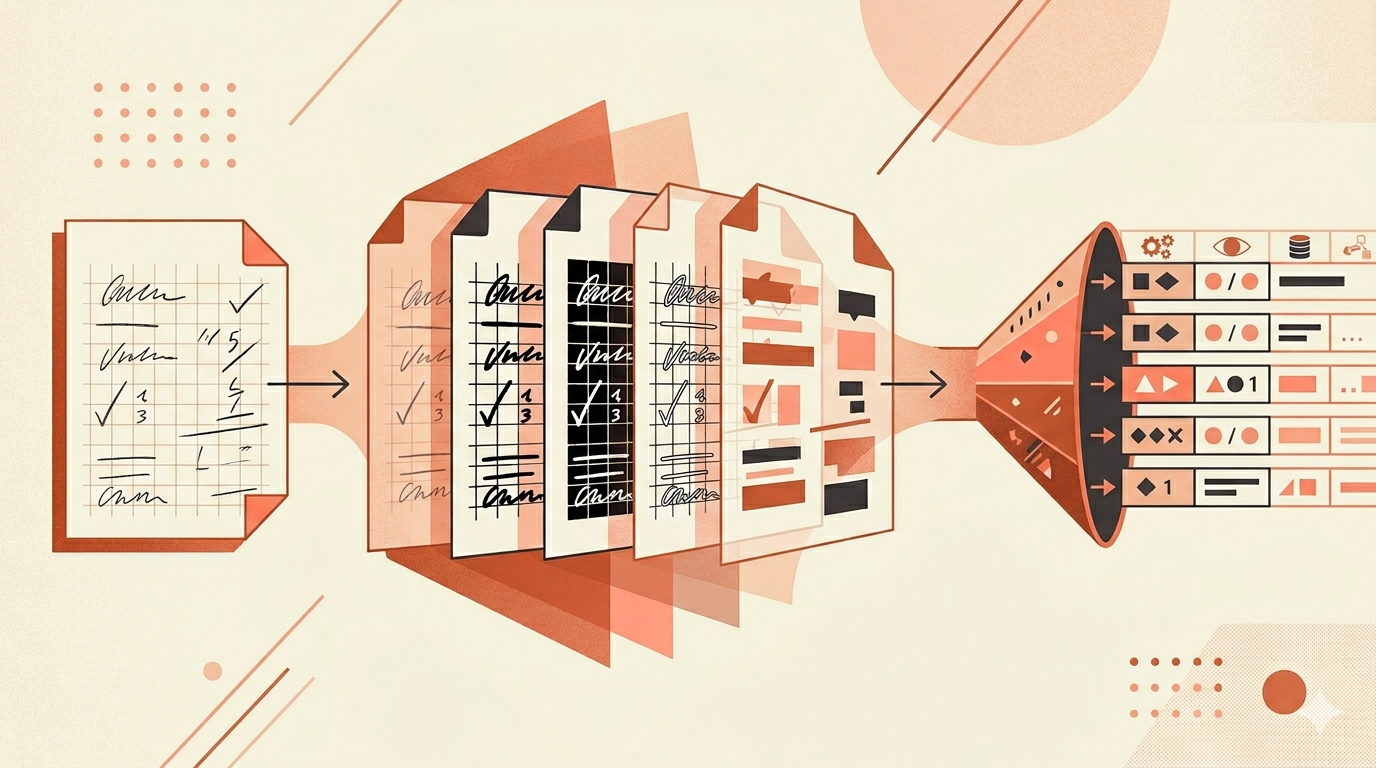
เตรียมภาพ 5 เวอร์ชัน
ผมเอาภาพต้นฉบับมาสร้างเป็น 5 แบบ แต่ละแบบเน้นแก้ปัญหาคนละจุด:
- ภาพต้นฉบับ — ไม่แตะอะไรเลย ใช้ภาพแบบดั้งเดิม
- CLAHE Enhancement — ปรับ contrast เฉพาะจุดที่มืดเกินไป
- Adaptive Threshold — แปลงเป็นขาวดำเพื่อให้ตัวเลขชัดขึ้น
- Sharpen + Denoise — เพิ่มความคมและลด noise
- Rotation + Deskew — แก้มุมเอียงให้ตรง
ส่งให้ Gemini 2.5 Flash อ่าน
ส่งภาพทั้ง 5 เวอร์ชันให้ Gemini อ่านแยกกัน ใช้ structured prompt บอกชัดเจนว่าต้องอ่านตัวเลขจากช่องไหนบ้าง เหมือนให้คน 5 คนนั่งอ่านเอกสารคนละสำเนา
โหวตคำตอบ
เอาผลจาก 5 เวอร์ชันมาโหวตกัน — ใช้ weighted voting โดยให้น้ำหนักตาม confidence ของแต่ละเวอร์ชัน ถ้า 3 จาก 5 ตอบเหมือนกัน ก็ใช้คำตอบนั้น
ตรวจ checksum
ตัวเลขคะแนนเลือกตั้งมี property ที่ตรวจสอบได้ คือผลรวมต้องตรง ถ้า checksum ไม่ผ่าน ผมจะกลับไปเลือกเวอร์ชันที่ผ่าน checksum แทน
จัดรูปแบบผลลัพธ์
ทำความสะอาด จัดเป็น CSV ตรวจ edge cases เช่น ช่องว่าง หรือตัวเลขที่อ่านได้แปลกๆ
เทคโนโลยี
โครงการเต็ม
ดาวน์โหลด Jupyter Notebook พร้อมโค้ดทั้งหมด